What Makes a Data Management Platform Special
Every data platform vendor will tell you they're "AI-native" and "cloud-first." Strip away the marketing and what's actually left?
I've been evaluating data management platforms for a while now, and I keep coming back to four things that matter. Four pillars that tell you whether a platform will hold up under real workloads or fall apart the moment you push past a proof of concept.
Let's get into it.
Pillar 1: Data Governance
Governance is the foundation. Everything else sits on top of it.
We're feeding data to LLMs, recommendation engines, fraud detection models. The stakes are different now. A bad number on a dashboard is embarrassing. A biased model output is a regulatory event. You need a governance office in place before you start thinking about anything else.
Data Quality has to be a first-class feature, not a bolt-on. The platform should give you automated profiling, validation rules that kick in before bad data hits downstream systems, anomaly detection that catches drift early, and lineage tracking so you can trace a bad output to its source. If you can't answer "where did this column come from and what happened to it along the way," you're not production ready.
Data Access is where things get interesting. Most organizations start with RBAC, role-based access control. You define roles like analyst, engineer, admin, and each role gets permissions. It works fine until it doesn't. Once you're managing hundreds of roles just to cover every combination of team, project, and sensitivity level, you've hit what practitioners call "role explosion."
That's where ABAC comes in. Attribute-based access control makes access decisions dynamically. Instead of assigning static roles, the system evaluates attributes at query time: the user's department, the data's classification, the purpose of the query. One policy can replace dozens of roles. Databricks recently shipped ABAC in Unity Catalog with governed tags that drive column masking and row filtering at the catalog level, inheriting downward through schemas and tables automatically. That's the direction modern platforms need to go.
The best platforms support both. RBAC for the simple cases, ABAC for everything else.
Data Masking is the one that most platforms get wrong. Basic masking gives you two options: show the column or hide it. Real requirements are way more nuanced than that.
Think about a healthcare dataset. A data scientist building a population health model needs age ranges and diagnosis codes but not names or SSNs. A compliance officer needs full visibility for audits. A third-party researcher needs everything anonymized.
This is multi-level column-level masking. The same column, different masking functions, applied dynamically based on who is running the query. When you pair this with ABAC policies, you get a single table serving multiple audiences at different levels of visibility. No copies. No stale duplicates. One governed source of truth with contextual access.
If the platform can't do this natively, you'll end up building it yourself. And that's a governance gap waiting to bite you.
Pillar 2: AI Readiness
Governance tells you if your data is trustworthy. AI readiness tells you if the platform can actually serve that data to the systems consuming it.
The AI landscape has moved past batch training jobs on Spark clusters. We're in the age of agentic AI. Autonomous agents that query data in real time, invoke tools, and make decisions on the fly. The question isn't "can my platform store data for ML?" It's "can my platform participate in AI workflows as a first-class citizen?"
This is where the Model Context Protocol comes in. MCP is an open standard introduced by Anthropic and now under the Linux Foundation. It gives LLM applications a standardized way to connect to external data sources and tools. OpenAI, Google DeepMind, and Microsoft have all adopted it. Thousands of MCP servers are already in production.
So ask your platform vendor: do you expose an MCP server? Can an AI agent query your catalog, read your metadata, and retrieve governed datasets through a standardized protocol? Or does every integration require a custom connector that your team builds and maintains?
A platform that's truly AI-ready doesn't just store data for AI. It exposes schema definitions, lineage graphs, and quality metrics in formats LLMs can consume. It supports the full ML lifecycle with feature stores, model registries, experiment tracking, and integrations with frameworks like MLflow and Hugging Face. If the platform treats AI as someone else's problem, it's already behind.
Pillar 3: Operational Readiness and Interoperability
The most capable platform in the world is useless if your team can't figure it out or it doesn't talk to anything else in your stack.
Learning curve matters more than people think. What does day one look like for a data analyst? For a data engineer? For a business user who just needs to find a dataset?
Snowflake's adoption isn't accidental. SQL-first means any analyst can be productive almost immediately. Databricks offers more raw power but demands more: distributed computing concepts, cluster configuration, comfort with notebooks and multiple languages. Both are valid, but they serve different audiences.
A good platform invests in consumer-grade experience on top of enterprise-grade infrastructure. A searchable catalog. Visual lineage. Quality dashboards in plain language. If someone needs a week of training just to find a dataset, that's a design problem.
Interoperability is non-negotiable. Your org probably runs Databricks for engineering, Snowflake for analytics, Informatica or Fivetran for integration, dbt for transformations, and some flavor of AWS, Azure, or GCP underneath.
The platform has to play well with all of it. That means open format support like Iceberg, Delta Lake, and Parquet so your data isn't locked in. Standard connectivity through JDBC, ODBC, REST APIs, and increasingly MCP for AI-native integrations. Cross-platform governance that enforces policies regardless of which compute engine runs the query. And metadata interoperability with catalog tools like Collibra, Atlan, or Alation.
A platform that does everything adequately but integrates with nothing isn't a platform. It's a silo with good branding.
Pillar 4: Cost Framework
Every platform conversation eventually lands on cost. It should, because the gap between the cheapest and most expensive way to run the same workload is enormous.
The pricing models are all different. Snowflake uses credits with per-second billing and auto-suspend, which works well for bursty analytics with idle periods. Databricks charges in DBUs but separates its fees from the underlying cloud bill, so you're effectively paying two invoices. Cloud-native options like BigQuery charge per bytes scanned, Redshift charges per node-hour, and Synapse uses DWUs.
But sticker price is only part of the picture. Total cost of ownership includes operational overhead (how many engineers to keep things running), egress costs (moving data between clouds adds up fast), edition gating (governance features often live behind premium tiers), and idle costs (misconfigured clusters running 24/7 will quietly eat your budget).
The right question isn't "which is cheapest?" It's "which gives me the best capability-to-cost ratio for my workload?" A platform that costs more per compute unit but saves you three engineers in ops might be the better deal. A platform that's cheap for storage but brutal on egress might cost more in a multi-cloud setup.
Model your top ten workloads. Estimate volumes and query patterns. Factor in the human cost. Then compare.
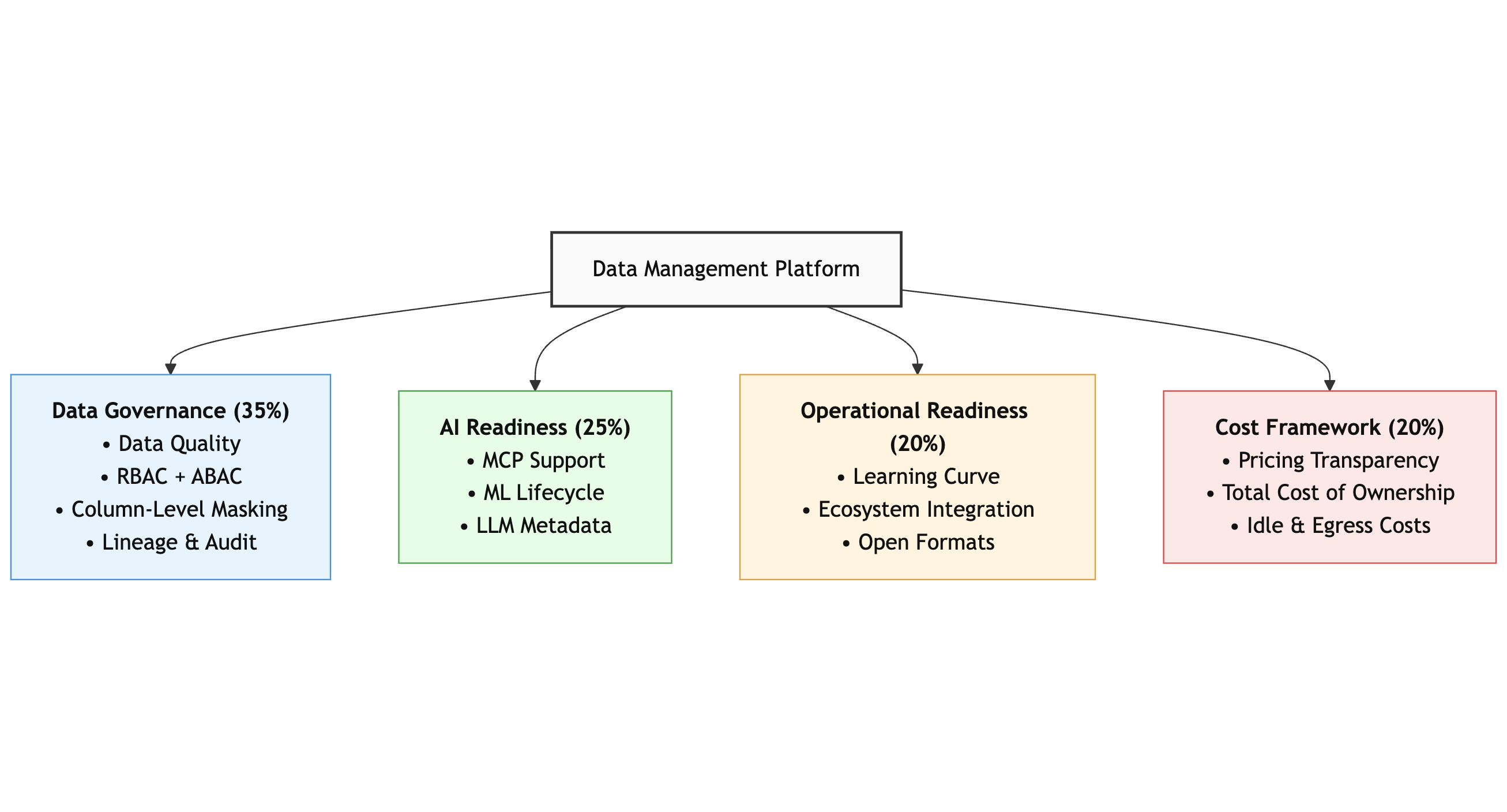
Putting It Together: A Weighted Framework
Here's how I'd score any platform against these four pillars. Rate each sub-criterion on a 1 to 5 scale, multiply by the weight, and you get a defensible comparison.
| Pillar | Weight | What You're Scoring |
|---|---|---|
| Data Governance | 35% | Data Quality (10%), Access Control with RBAC+ABAC (10%), Multi-Level Column Masking (10%), Lineage and Auditability (5%) |
| AI Readiness | 25% | MCP and Protocol Support (8%), ML Lifecycle Integration (7%), Metadata for LLMs (5%), Agentic AI Support (5%) |
| Operational Readiness | 20% | Usability and Learning Curve (7%), Ecosystem Integration (7%), Open Format Support (6%) |
| Cost Framework | 20% | Pricing Transparency (5%), TCO for Your Workloads (8%), Idle Cost Management (4%), Multi-Cloud Efficiency (3%) |
Before you even start scoring, these should be pass/fail gates:
- Native policy-based governance. If it's not built in, it's disqualified.
- Column-level masking with multi-level support. Non-negotiable for PII, PHI, or financial data.
- Open format support. If your data is locked in a proprietary format, walk away.
- Programmatic API access. If you can't automate governance and deployment through APIs, it doesn't belong in a modern stack.
Bottom Line
The platform landscape is converging. Snowflake is pushing into AI and open formats. Databricks is simplifying ops and adding governance. Cloud services are bolting on lakehouse features. The lines are blurring.
But convergence doesn't mean equivalence. The details live in these four pillars. Governance depth, AI readiness, operational polish, and cost transparency are what separate a platform you can build on from one you'll replace in eighteen months.
Don't buy the marketing. Score the platform.