Data Products: What, Why, and How
What Are Data Products?
The term is new. The idea is not.
Every time a business has tried to make its data more reliable, more usable, more governed, it has been chasing the state of a data product without calling it one. A data product is not a dataset. It is not a dashboard. It is not a pipeline. It is all of them working together as one deployable, manageable, and trustworthy unit.
In the software world, a product ships with its code, its infrastructure, its documentation, and its interfaces. A data product applies the same thinking to data. It wraps together the data itself, the code that processes it, the metadata that gives it meaning, and the infrastructure that keeps it running.
Purpose defines what the data should deliver. Execution defines how it gets there. A data product lives at the intersection of both. Strip away either and you are left with just another data initiative that sounds great in a strategy deck but delivers nothing on the ground.
Why Data Products Right Now?
We called data an asset for years but treated it like exhaust. Pipelines were scattered, governance was reactive, metadata was incomplete, and the people producing data had zero visibility into how it was consumed downstream. That worked when the stakes were low. The stakes are no longer low.
- Data and code finally need each other. Software has always coupled features with code for discipline and ownership. Data never did. Organizations now realize that applying the same principle to data is not optional, it is survival.
- AI raised the bar. Data consumers are no longer just analysts on dashboards. Models, agents, and automated systems need data that is semantically rich, contractually guaranteed, and programmatically accessible. Traditional data management was never built for that.
- The cost of unmanaged data became undeniable. Broken pipelines, duplicated efforts, shadow datasets, compliance firefighting. The compounding debt of treating data casually finally hit a tipping point that leadership could no longer ignore.
- Self serve is no longer a nice to have. Teams want to discover, access, and use data without filing tickets or waiting on a central team. That demands a product mindset, not a pipeline mindset.
Essential Components of a Data Product
A data product is a composition of four structural pillars. Each is essential. Remove any one and the product breaks.
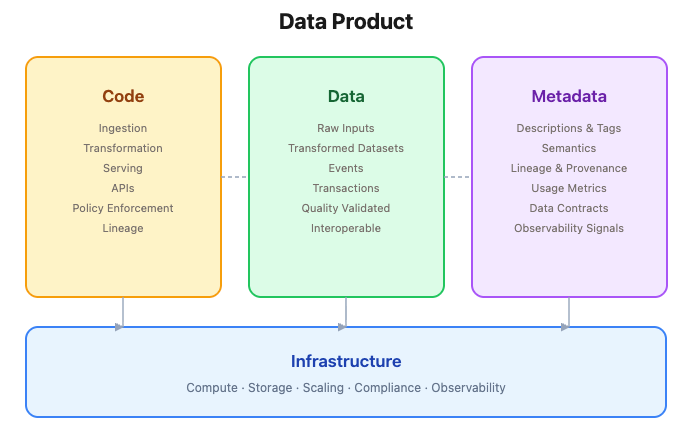
Code
Code is what makes a data product actually work. Ingestion, transformation, serving, APIs, policy enforcement, lineage, compliance. All of it.
The reason data has historically been less reliable than software is simple. We never treated data code with engineering discipline. Most stacks have code scattered across tools that cannot talk to each other. We talk about data silos constantly but rarely acknowledge the deeper problem: data code silos.
A real data product puts all code under one repository. Versioned, modular, testable, deployable as one unit. As this matures, expect a shift from imperative plumbing to declarative, intent driven development. You describe what you want, the platform figures out how.
Data
The raw material. Customer records, transactions, events, measurements. Everything the business acts on, whether raw or transformed.
But raw data alone is not a product. It must meet quality standards, be structured for interoperability, and be validated for accuracy. Without enforcement, you are just gift wrapping garbage.
The interesting pattern emerging is data products as composable building blocks. Instead of every team building from scratch, they consume and extend existing products. Each new data product makes the next one cheaper and faster. That compounding effect is the real unlock.
Metadata
Data without metadata is a locked room with no key. It includes descriptions, tags, profiles, usage metrics, semantic definitions, lineage, provenance, and observability signals. It is what pulls data out of the graveyard of dark data, information that exists but stays dormant because nobody can find it.
Data contracts fit naturally here. A contract is metadata plus enforcement. Declarative specifications, guaranteed adherence, seamless change management.
Looking ahead, metadata becomes the primary interface for AI agents interacting with data products. When an agent needs to discover, evaluate, and consume data autonomously, metadata is the machine readable handshake. Investing in rich metadata today is future proofing for agentic workflows tomorrow.
Infrastructure
The stage on which everything runs. Compute, storage, governance, orchestration, all declaratively managed.
Good infrastructure makes a data product self contained. It handles scaling, compliance, observability, and resource allocation. Without it, data products depend on external systems, which defeats the point.
More importantly, the right infrastructure democratizes building. When the platform handles the plumbing, any data developer becomes a data product developer. The next evolution is infrastructure that is not just supportive but intelligent. Auto scaling on consumption patterns, automated cost optimization, self healing based on observability signals. Not configured, but declared.
Characteristics of a Data Product
Components build the product. Characteristics define how it behaves in the wild.
Natively Discoverable. If people cannot find it, it does not exist. Titles, descriptions, tags, and categories should make any data product locatable without tribal knowledge or Slack archaeology.
Easily Accessible. Discovery without access is a tease. Consumers should be able to connect and consume through well defined output ports with zero friction, no tickets, no waiting.
Secure. Access controls and masking policies are not an afterthought. They are baked in from day one with clear ownership and explicit rules on who sees what.
Interoperable. Data products must talk to each other. Shared semantics, compatible schemas, and open interfaces prevent you from building a new generation of silos dressed up in modern vocabulary.
Independent. Every dependency is contained within the product boundary. No external teams needed to deploy, maintain, or evolve it. Independence is what makes the model scale.
Separate. Clear boundaries between products. Changes to one should never cascade into breaking another. Isolation ensures accountability and prevents the kind of invisible coupling that has haunted data teams for years.
The Bigger Picture
Data products are not a revolution. They are a reckoning. We have always wanted data that is trustworthy, accessible, and well governed. What we lacked was the discipline and the framework to deliver it consistently.
The shift from data as infrastructure to data as product changes everything: how teams collaborate, how decisions get made, how fast organizations move, and how much value data actually generates. It forces a question that should have been asked long ago but rarely was: does this data initiative directly serve the business, or are we building because we can?
The organizations that will win are not the ones with the most data. They are the ones that treat data with the same product rigor they apply to their customer facing software. That means ownership, quality, iteration, and a relentless focus on the consumer experience.
Data products are how we get there.